
Building an AI-Assisted Stock Prediction System
經過之前AI協作產生的系統,因為Gemini在協作的過程中,為了趕快配合我,直接把一些數據寫死,造成預測一直很詭異,我建立的AI股票模擬專家團隊,還會會議我的持股,也沒太大的作用,都叫我賠錢脫手…..後來,我看了許多股市影片,發現我沒設定好特徵,也沒建立AI模型運算,只靠相信著自信滿滿的Gemini,是一個嚴重的問題,問題不只是 AI 不夠聰明,而是我一開始就沒把系統的骨架搭好。特徵沒設好、模型沒真正建立、資料流程也不夠乾淨,最後就算再相信 Gemini,也只是在相信一個看起來很會說話產生的版本。
於是我直接重新來過,開始了準準準7.0 (前面的都失敗了 失敗…..),我規劃了LLM與機器學習模型XGBoost來做系統的預測,以資料採集、自動清洗、多維度特徵提取、防呆濾網與機器學習打分來建立個股的預測,這次我不想再只靠想像,而是直接把系統拆成幾個真的有用的部分:資料採集、自動清洗、多維度特徵提取、防呆濾網,還有機器學習打分。
簡單講,就是先把資料弄對,再讓模型去學,最後再用規則把明顯不合理的東西擋掉。
有時我在想…是我在訓練AI還是AI在訓練我,不過我發現Gemini好像變笨了,我就搜尋關於降智,查到了一個AI Stupid Level「AI 降智儀表板」。
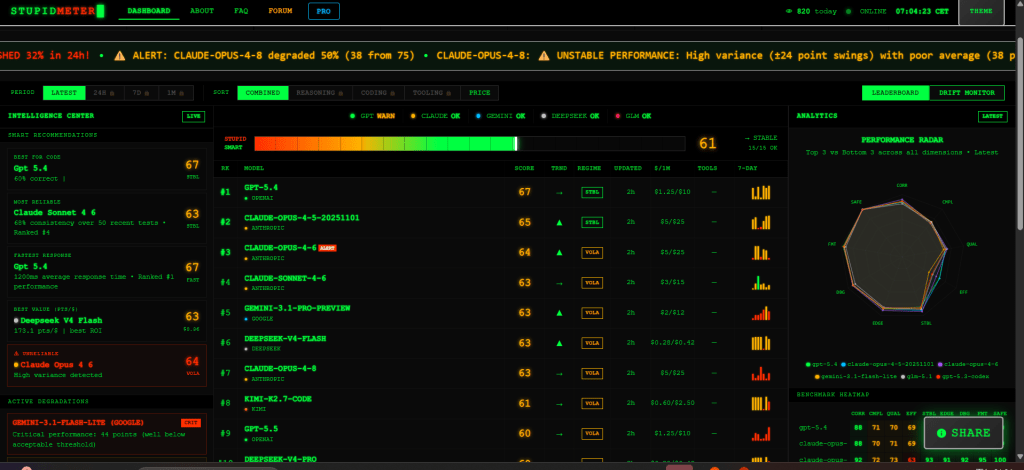
發現Gemini是真的低於標準…..
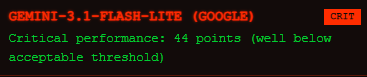
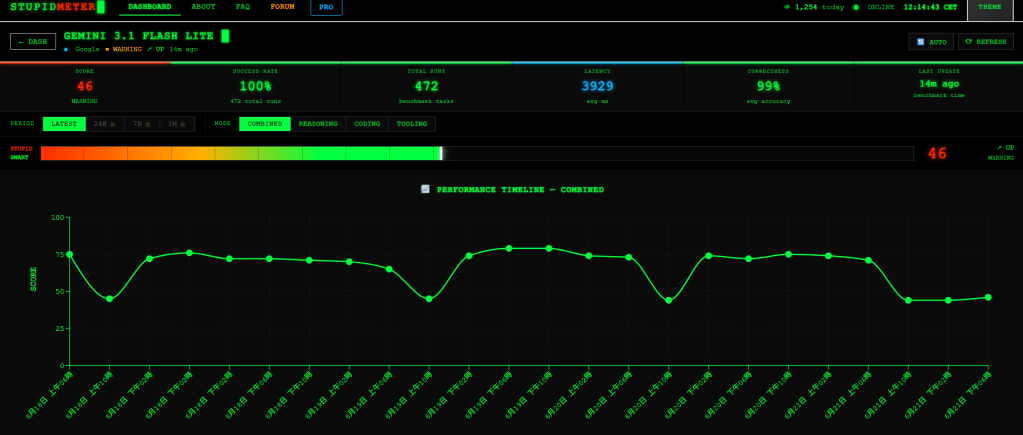
不過,總是有方法的,就是面對Gemini要多次驗證浪費點時間就是了….哈,話說回準準準7.0系統,我以能不能真的拿來用來思考,畢竟之前的失敗已經有經驗了…..
1. 先把資料抓對
這件事其實最重要。
因為如果資料本身就錯了,後面不管你模型多強都沒用。
我現在會去抓台股的盤後資料、籌碼資訊、成交量、融資融券,還有美股的即時報價和一些新聞來源。
我的想法很單純:不要只看單一面向,至少要讓系統知道市場是怎麼動的,不要只看價格,卻完全沒看到資金跟消息。
2. 再把資料整理成能用的特徵
這一步其實就是我之前最缺的地方。
以前我可能想太多,把系統搞得很複雜,卻沒有真的把「什麼才是有效訊號」想清楚。
所以這次我把重點放在幾個比較實際的方向:
- 成交量有沒有突然放大。
- 股價是不是一下子漲太快或跌太快。
- 外資、投信、自營商是不是有連續動作。
- 公司基本面是不是有問題。
- 新聞情緒是不是有明顯偏多或偏空。
我不想再把一堆技術指標塞進去,因為那種東西太容易看起來很完整,但實際上不一定真的有幫助。
我現在比較在意的是:這檔股票到底有沒有「市場正在注意它」的跡象。
3. 最後才交給模型打分數
這次我才真正開始用 XGBoost 這類模型去做預測。
不是那種拿來裝飾的模型,而是真的讓它根據我整理好的特徵去學習、去判斷。
但我也很清楚,AI與模型不是神。
所以我不會把它當成唯一答案,而是讓它跟一些防呆條件一起工作。
例如成交量太低的先排掉、明顯不合理的標的先擋掉、基本面太差的先扣分。
我寧可少看一點,也不要再去接那些看起來熱鬧、實際上很危險的東西。
這次和前面最大的差別
前面幾版,我太想把系統做得像一個完整的 AI 團隊,結果反而離我自己真正需要的系統越來越遠。
我知道自己不是在做什麼大型機構級系統,我只是想做一個能幫我判斷的工具。
所以這次的準準準 7.0,不是什麼「AI 專家會議室」,也不是什麼很炫的黑盒子。
- 先把資料弄真。
- 再把特徵弄對。
- 然後讓模型去學。
- 最後加上防呆濾網,避免自己又被市場騙一次。
這次的資訊我也改成隔日預測,但….經過幾天下來勝率還蠻低的。

反正系統不是寫出來就會準,這次比較接近真實,我會持續修正,也實驗AI協作變化,這些AI有些部分進步但有些部分卻退步了。
後續我再把調整過的分享,2勝/7戰…….哈 準準準7.0還不準。

發表留言