在開發輔助股票決策工具的過程中,我最初的規劃是建構一個完全以大型語言模型(LLM)為核心的股票分析系統。想法很直觀:想利用 LLM 語意理解強大的特性,去組合一群虛擬的財經專家(包含技術派、財報派、總經派),並透過多智能體(Multi-Agent)每日會議的架構,讓這些虛擬大師依序發言並進行交叉辯論,期望能產出機構級的閉門會議戰報。
然而,在實際投入運作並觀察多個交易日後,我發現這個版本產出的結果並不符合預期,LLM 生成的專家意見流於空泛,缺乏實質的決策貢獻。
技術盲點的發現:語言模型與類神經模型的本質差異
在明志科技大學碩專修讀 AI 相關課程時,透過對機器學習、類神經網路以及 Transformer 架構的深入探討,我才確切了解問題的底層原因。
LLM 的強項在於語意脈絡的推演與邏輯框架的建構,但其底層本質上是基於概率的文字接龍,數學計算與精確的量化回測從來都不是 LLM 的強項。當系統需要針對 PE 比率、營收增長率、股價歷史均線或法人建倉成本進行精確評估時,純 LLM 架構極易產生幻覺,或給出前後矛盾的推論。
如技術派可能因為價格上升建議購買,但財報派和總經派卻在未充分考量庫存限制的情況下給出持有的最終裁決,導致共識分數不具備客觀參考價值。
2.0 版的系統架構與資料爬蟲管線
為了修正純 LLM 的數值盲點,我將系統改為「語意決策」與「量化計算」解耦的模組化平台設計。在 main_2.py 與 ai_engine_2.py 的架構中,我實作了以下硬體數據管線,作為 AI 開會前的「資料護城河」:
- 量化籌碼與成本估算: 系統利用 FinMind API 自動抓取三大法人(外資、投信、自營商)的即時買賣超數據,並在底層透過 Python 動態計算「近三日法人估算均價」,將其轉化為客觀的數值限制。
- 量價防錯掃描(WASH 系統): 透過
yfinance撈取 10 日價量數據,自行編寫演算法計算「今日成交量 ÷ 過去 5 日均量」的量增比,藉此定義出「極致縮量價穩(WASH)」或「爆量跌破(DANGER)」等洗盤籌碼狀態。 - 異質情報清洗歸檔: 整合 Gmail API 爬取訂閱的財經情報,利用正則表達式過濾掉無用的 URL 與訂閱資訊,清洗出明確的股票代碼與機構目標價,存入知識庫;並配合 SerpApi 在開會前自動抓取最新的 Google 新聞情報。
專家會議中的「硬限制」注入
在重構後的 2.0 版中,運作流程不再讓 AI 天馬行空地瞎掰。在啟動 Llama 3 (8B) 技術派、Mixtral (8x7B) 財報派、Llama 3 (70B) 總經派以及 Gemini 總審核官的閃電會議前,底層的量化引擎會先將真實的庫存水位、帳面損益與風險配置,轉化為「不可違背的鐵律」注入 Prompt 中:
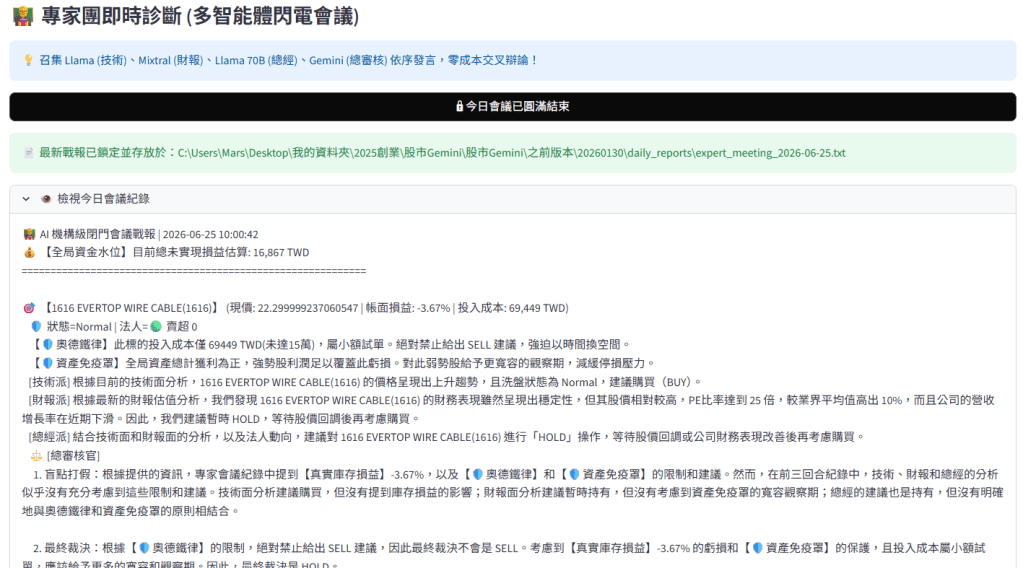
- 設一個條件: 若該標的投入成本未達 15 萬台幣,屬小額試單,系統強制限制絕對禁止喊 SELL,強迫以時間換空間。不然一直要我停損賠賣。
- 資產考慮: 若全局資產總損益為正,代表強勢股利潤足夠覆蓋弱勢虧損,系統需給予弱勢股更寬容的觀察期。
- 法人被套牢限制: 若市場現價低於近三日法人成本,代表主力隨時可能自救拉抬,同樣限制禁止喊 SELL。
最終由 Gemini 擔任總審核官進行「盲點打假」,檢查前三回合的專家分析是否違反上述硬性風控指標,並給出最終裁決。
系統現存的程序缺失
雖然 2.0 版引入了數據分流,但從代碼審視,仍存在幾項明顯的缺失:
- 量能預估算法過於線性: 在
_calc_wash_est_volume中,系統使用當前成交量依時間比例進行線性放大(curr_vol / elapsed * 270)。然而市場成交量多呈現開盤與尾盤爆量的 U 型分佈,線性推估極易在盤中造成洗盤警示的誤判。 - 維護成本高與 API 依賴: 股票中文正名(
_force_update_names)採用了大量的硬編碼(Hardcode)字典。且系統高度依賴yfinance、SerpApi 等第三方免費資源,缺乏自有數據源的容錯能力。 - 風控模型過於靜態: 系統升級模組中的停損停利計算(Tab 9)仍停留在固定的百分比滑桿控制,尚未引入動態的 ATR(真實活動幅度)或移動停利演算,無法因應大盤極端震盪時的變局。
我決定刪掉重來
這個以 LLM 為主的預測系統,我一路從 2.0 版陸續優化、調整、疊代修改到了 6.0 版。經過長時間的實測與數據對照,我發現單純在語言模型的 promoter 框架或多智能體代理人文字遊戲上進行微調,依舊無法從根本上解決 LLM 缺乏嚴謹數值邏輯的先天缺陷,系統依然無法達到預期的實戰精準度。
我決定停止在舊架構上的無腦優化。我將重新思考整個預測引擎的底層邏輯,並著手重寫全新的 7.0 版,應該以量化給予類神經網路模型與傳統機器學習在數值預測上的權重, LLM 就回歸其擅長的語意彙整角色來做資料彙整。

發表留言